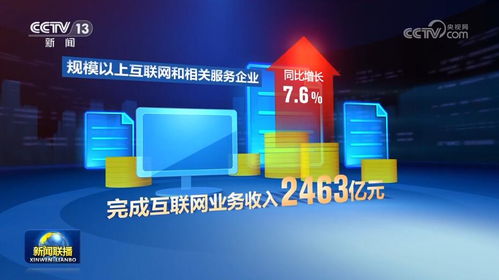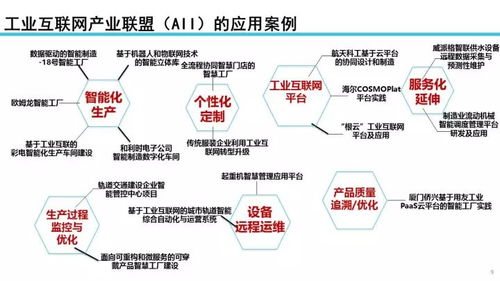
2019年,數控裝備工業互聯通訊協議(NC-Link)及其應用案例成功入選工業互聯網產業聯盟優秀案例,標志著中國在工業互聯網數據服務領域取得了突破性進展。這一成果展示了NC-Link協議如何通過標準化通訊架構,有效解決制造業中設備互聯互通和數據共享的痛點。
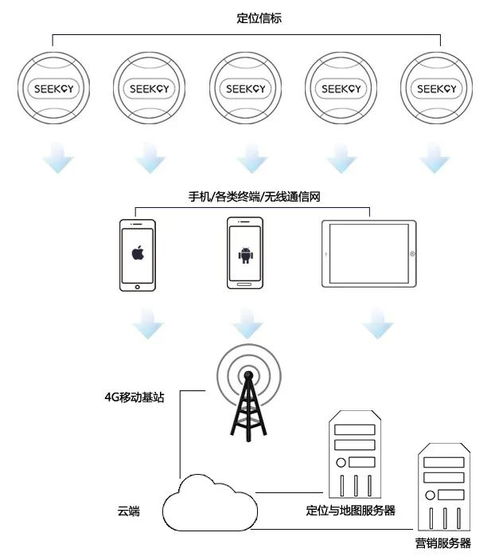
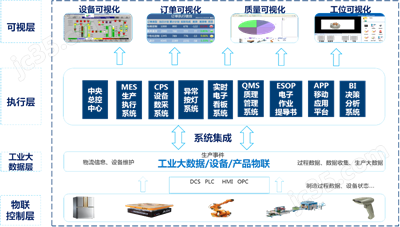
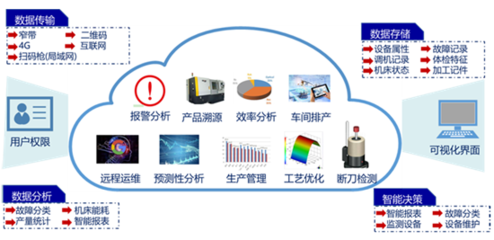
NC-Link協議的核心價值在于其針對數控裝備的專有設計,它不僅支持多品牌、多型號設備的統一接入,還能實現生產數據的實時采集與傳輸。在應用層面,該協議通過定義統一的數據格式和通訊接口,顯著降低了企業實施工業互聯網的集成成本。例如,在智能工廠場景中,基于NC-Link的解決方案能夠將機床、機器人等設備的生產狀態、工藝參數和質量數據無縫對接至云端平臺,為生產優化、預測性維護和供應鏈協同提供數據支撐。
此次入選優秀案例,充分證明了NC-Link在推動工業互聯網數據服務標準化和產業化方面的示范作用。隨著該協議的持續推廣,預計將加速制造業數字化轉型進程,為構建高效、智能的工業生態奠定堅實基礎。